Machine learning aims at developing computer systems that can perform tasks without explicit instructions and improve themselves with experience, where the experience is encoded as data. Machine learning for biology and medicine apply and develop machine learning approaches to integrate and analyze biological data to answer key questions in biology and medicine.
Advances in molecular profiling technologies have resulted in large quantities of data, turning biology into a data rich field. A multitude of datasets collected from both normal and disease tissues is now available for large cohorts. Our research aims at using this data effectively to deepen our understanding of the molecular basis of the workings of the cell, diseases, and to translate this knowledge into clinics for improving patient care. The methods we develop rely on a wide range of machine learning approaches, including deep learning, kernel-based methods, graph machine learning. For more information, please visit our research group page.
Website

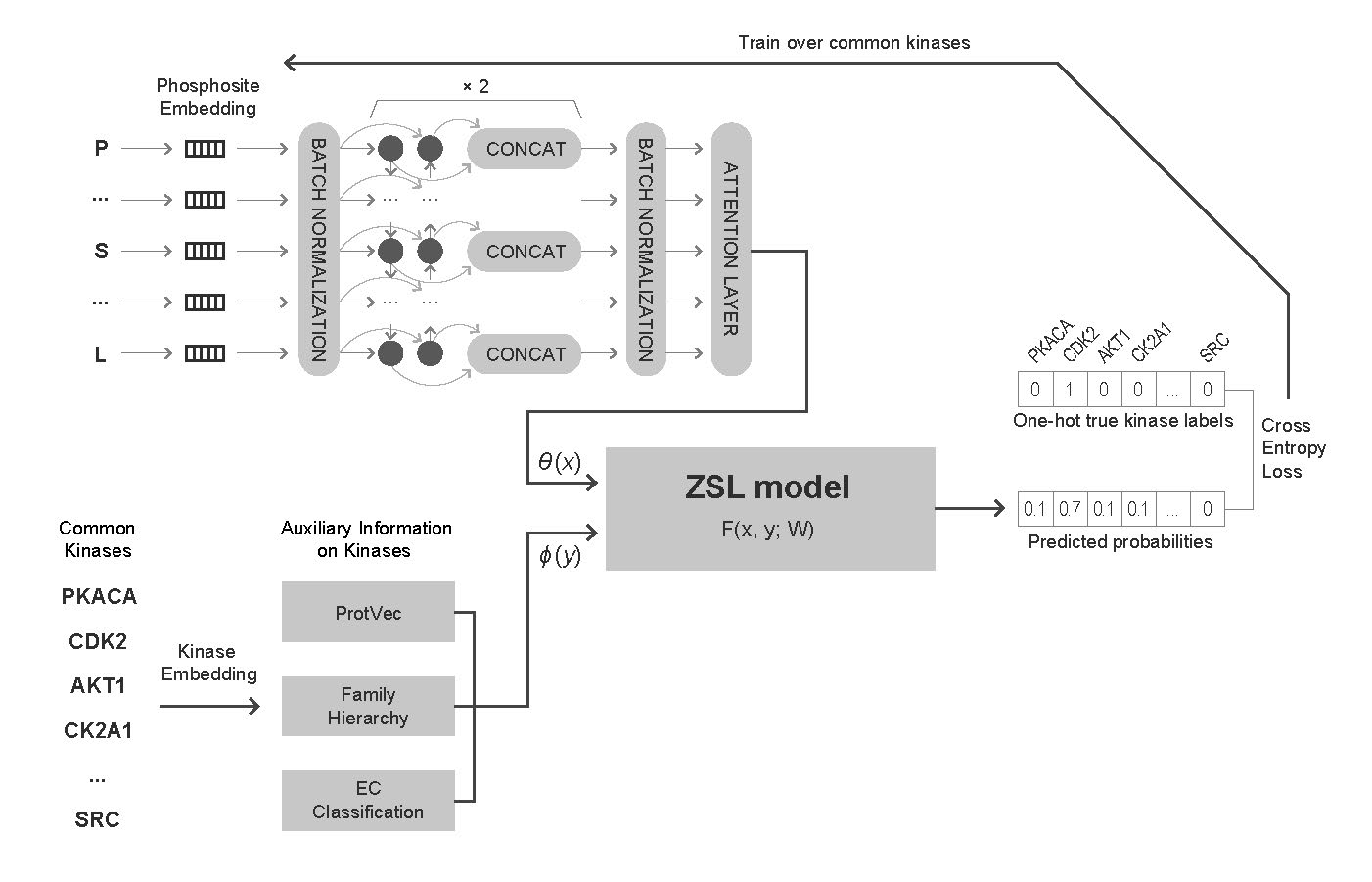
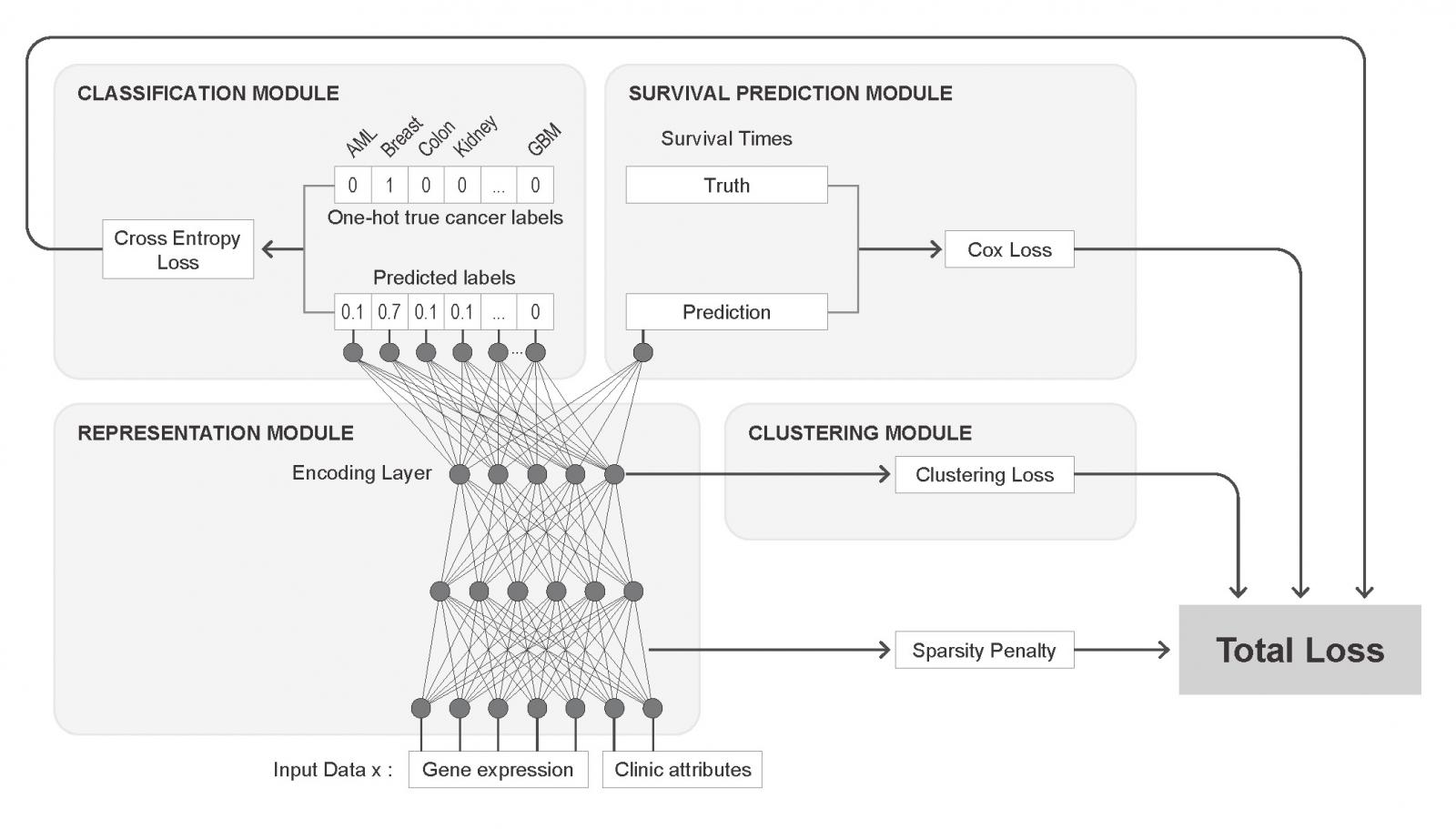
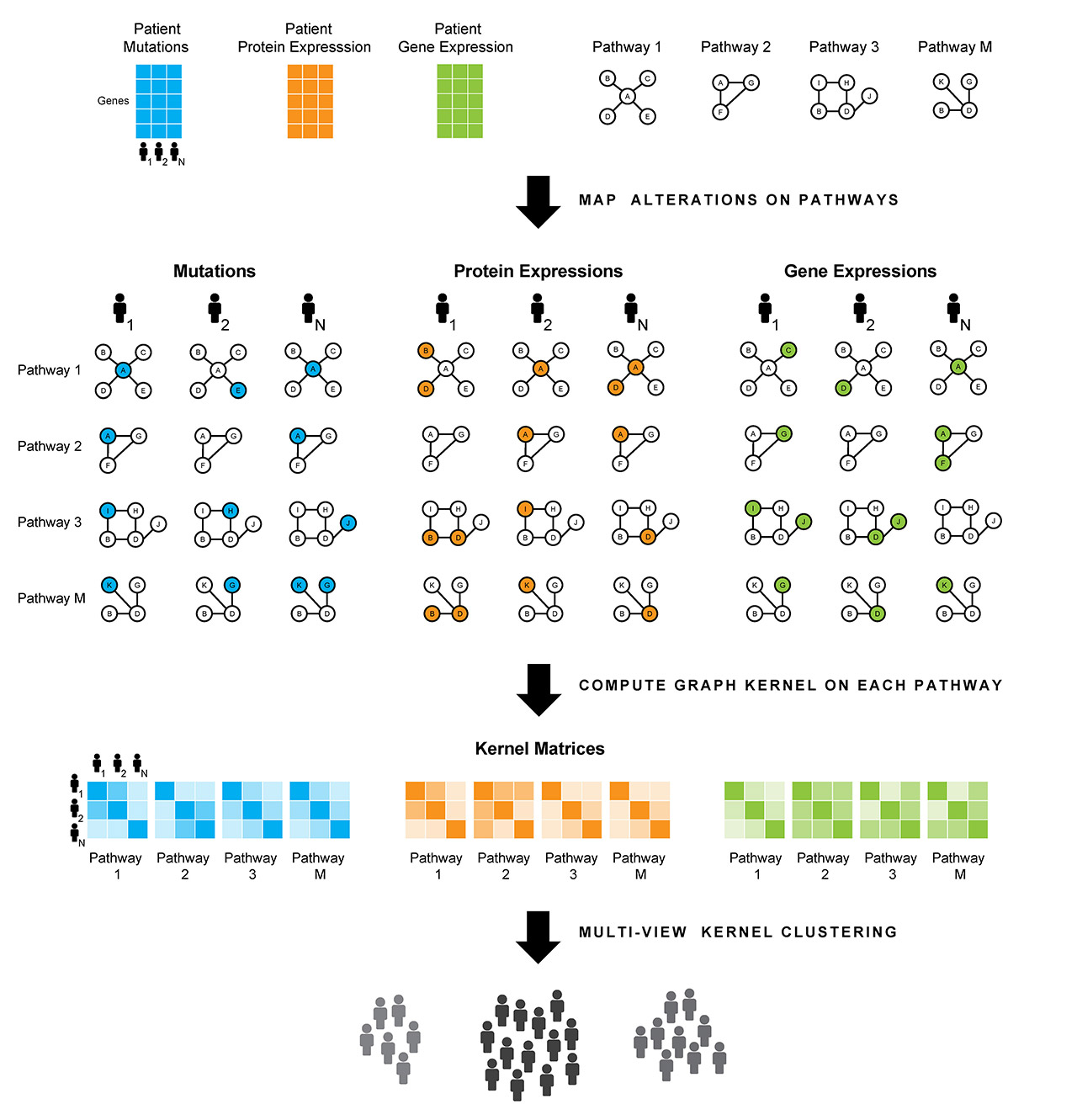
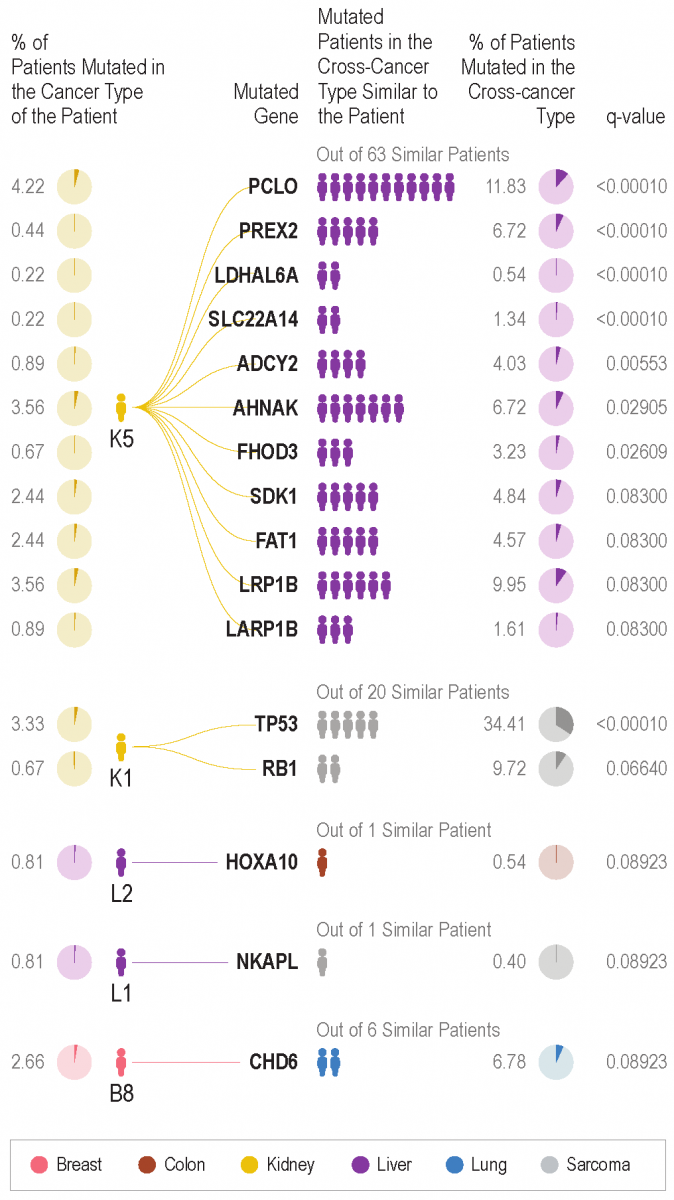
{kind=link}